In this paper we consider the
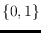
-string searching problem. For a given set
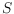
of binary strings of fixed length
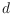
and a query string
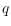
one asks for
the most similar string in
. Thereby the dissimilarity of two given
strings is the number of disagreeing bits, that is, their Hamming distance.
We present an efficient
-string searching algorithm based on
hierarchical pre-clustering. To this end we give several useful observations
on the inter- and intra-cluster distances.
The presented algorithms are
easy to implement and we give exhaustive experimental results for uniformly
distributed sets as well as for specially chosen strings. These experiments
indicate that our algorithms work well in practice.